Hive Integration with Spark
Are you struggling to access hive using spark?
Is your hive table is not showing in spark?
No worry here I am going to show you the key changes made in
HDP 3.0 for hive and how we can access hive using spark.
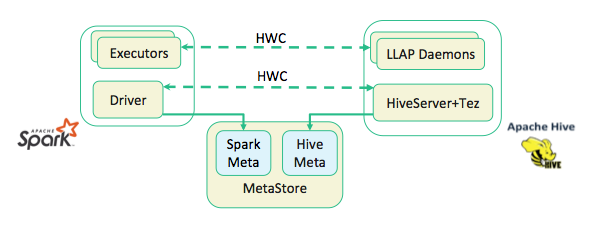
Now in HDP 3.0 both spark and hive ha their own meta store. Hive uses the "hive" catalog, and Spark uses the "spark" catalog. With HDP 3.0 in Ambari you can find below configuration for spark.

As we know before we could access hive table in spark using
HiveContext/SparkSession but now in HDP 3.0 we can access hive using Hive Warehouse Connector.
Hive Warehouse Connector
A library to read/write DataFrames and Streaming DataFrames
to/from Apache Hive™ using LLAP.
Spark and Hive now use independent catalogs for accessing
SparkSQL or Hive tables on the same or different platforms. A table created by
Spark resides in the Spark catalog. A table created by Hive resides in the Hive
catalog. In Hive 3.0 and later, databases fall under the catalog namespace,
like how tables belong to a database namespace. Although independent, these
tables interoperate and you can see Spark tables in the Hive catalog, but only
when using the Hive Warehouse Connector
Apache Ranger and the HiveWarehouseConnector library provide
row and column, fine-grained access to Spark data in Hive.
The Hive Warehouse Connector supports the following
applications:
• Spark shell
• PySpark
• The spark-submit script
You can find connector jar at below location
/usr/hdp/3.0.0.0-1634/hive_warehouse_connector/hive-warehouse-connector-assembly-1.0.0.3.0.0.0-1634.jar
For pyspark
/usr/hdp/3.0.0.0-1634/hive_warehouse_connector/pyspark_hwc-1.0.0.3.0.0.0-1634.zip
You can download same from maven repository also
<!--
https://mvnrepository.com/artifact/com.hortonworks.hive/hive-warehouse-connector
-->
<dependency>
<groupId>com.hortonworks.hive</groupId>
<artifactId>hive-warehouse-connector_2.11</artifactId>
<version>1.0.0.3.0.1.0-187</version>
</dependency>
Apache Spark-Apache Hive connection
configuration
You can configure Spark properties in Ambari to use the Hive
Warehouse Connector for accessing data in Hive.
Prerequisites
You need to use the following software to connect Spark and
Hive using the HiveWarehouseConnector library.
• HDP 3.0
• Hive with HiveServer Interactive
• Spark2
Required
properties
You must add several Spark properties through spark-2-defaults in Ambari to use the Hive Warehouse Connector for accessing data in Hive. Alternatively, configuration can be provided for each job using --conf.
|
Property |
Description |
Comments |
Example |
|
spark.sql.hive.hiveserver2.jdbc.url |
URL for HiveServer2 |
In Ambari, copy the value
from Hive Summary > HIVESERVER2 JDBC URL. |
jdbc:hive2://localhost:10000 |
|
spark.datasource.hive.warehouse.metastoreUri
|
URI for metastore |
Copy the value from
hive.metastore.uris. |
thrift://sandbox.hortonworks.com:9083 |
|
spark.datasource.hive.warehouse.load.staging.dir |
HDFS temp directory for
batch writes to Hive |
For example, /tmp |
/tmp |
|
spark.hadoop.hive.llap.daemon.service.hosts |
Application name for LLAP
service |
Copy value from Advanced
hive-interactivesite >
hive.llap.daemon.service.hosts |
@llap0 |
|
spark.hadoop.hive.zookeeper.quorum |
Zookeeper hosts used by
LLAP |
Copy value from Advanced
hivesitehive.zookeeper.quorum |
host1:2181;host2:2181;host3:2181 |
Spark on a Kerberized YARN cluster
In Spark
client mode on a kerberized Yarn cluster, set the following property:
• Property: spark.sql.hive.hiveserver2.jdbc.url.principal
• Description: Must be equal to
hive.server2.authentication.kerberos.principal.
• Comment: Copy from Advanced hive-site
hive.server2.authentication.kerberos.principal.
In Spark cluster mode on a kerberized YARN cluster, set the following property:
• Property:
spark.security.credentials.hiveserver2.enabled
• Description: Must use Spark ServiceCredentialProvider
and set equal to a boolean, such as true
• Comment: true by default
Running spark shell with Hive
Warehouse Connector
In Spark
client mode on a kerberized Yarn cluster
spark-shell --jars /user/home/ashish/hive-warehouse-connector-assembly-1.0.0.3.0.0.0-1634.jar
--conf spark.hadoop.hive.llap.daemon.service.hosts=@llap0
--conf spark.sql.hive.hiveserver2.jdbc.url="jdbc:hive2://localhost:2181;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2"
--conf
spark.datasource.hive.warehouse.load.staging.dir=/tmp
--conf
spark.datasource.hive.warehouse.metastoreUri=thrift://sandbox.hortonworks.com:9083
--conf
spark.security.credentials.hiveserver2.enabled=false
In
Spark cluster mode on a kerberized YARN cluster
spark-shell --jars /user/home/ashish/hive-warehouse-connector-assembly-1.0.0.3.0.0.0-1634.jar
--conf spark.hadoop.hive.llap.daemon.service.hosts=@llap0
--conf
spark.sql.hive.hiveserver2.jdbc.url="jdbc:hive2://localhost:2181;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2"
--conf spark.datasource.hive.warehouse.load.staging.dir=/tmp
--conf
spark.datasource.hive.warehouse.metastoreUri=thrift://sandbox.hortonworks.com:9083
--conf spark.security.credentials.hiveserver2.enabled=true
--conf spark.sql.hive.hiveserver2.jdbc.url.principal=hive/_HOST@*****.COM
HiveWarehouseSession API
• Scala
import com.hortonworks.hwc.HiveWarehouseSession
import com.hortonworks.hwc.HiveWarehouseSession._
val sparkSession
= SparkSession.builder
.appName(SparkApplicationName)
.config("spark.hadoop.hive.llap.daemon.service.hosts",
"@llap0")
.config("spark.sql.hive.hiveserver2.jdbc.url", " jdbc:hive2://localhost:2181;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2")
.config("spark.datasource.hive.warehouse.load.staging.dir",
"/tmp")
.config("spark.datasource.hive.warehouse.metastoreUri", "
thrift://sandbox.hortonworks.com:9083")
.config("spark.sql.hive.hiveserver2.jdbc.url.principal",
"hive/_HOST@*****.COM")
.enableHiveSupport()
.getOrCreate()
• Java
import com.hortonworks.hwc.HiveWarehouseSession;
import static com.hortonworks.hwc.HiveWarehouseSession.*;
HiveWarehouseSession hive = HiveWarehouseSession.session(sparkSession).build();
• Python
from pyspark_llap import HiveWarehouseSession
hive = HiveWarehouseSession.session(sparkSession).build()
- Set the current database for
unqualified Hive table references
hive.setDatabase(<database>)
- Execute a catalog operation and return
a DataFrame
hive.execute("describe extended
web_sales").show(100)
- Show databases
hive.showDatabases().show(100)
- Show tables for the current database
hive.showTables().show(100)
- Describe a table
hive.describeTable(<table_name>).show(100)
- Create a database
hive.createDatabase(<database_name>,<ifNotExists>)
- Create an ORC table
hive.createTable("web_sales").ifNotExists().column("sold_time_sk",
"bigint").column("ws_ship_date_sk",
"bigint").create()
See the CreateTableBuilder interface section below for
additional table creation options. Note: You can also create tables through
standard HiveQL using hive.executeUpdate.
- Drop a database
hive.dropDatabase(<databaseName>, <ifExists>,
<useCascade>)
- Drop a table
- Execute
a Hive SELECT query and return a DataFrame.
Write operations
- Execute a Hive update statement
hive.executeUpdate("ALTER TABLE old_name RENAME TO new_name")
Note: You can execute CREATE, UPDATE, DELETE, INSERT, and MERGE statements in this way.
Java/Scala:
df.write.format(HIVE_WAREHOUSE_CONNECTOR).option("table", <tableName>).save()
Python:
df.write.format(HiveWarehouseSession().HIVE_WAREHOUSE_CONNECTOR).option("table",
&tableName>).save()
Reference:
0 Comments
Be first to comment on this post.