ADF Spark Activity
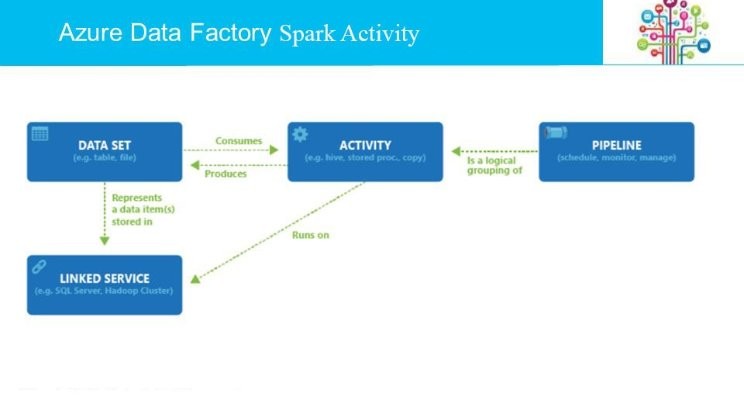
Introduction
Spark Activity is one of the data transformation activities supported
by Azure Data Factory. This activity runs the specified Spark program on your
Apache Spark cluster in Azure HDInsight.
Prerequisite
for ADF Spark Activity
1.
Create a Azure Storage Account and
select account type as Blob storage.
2.
Create an Apache Spark cluster in
Azure HDInsight and Associate the Azure storage account (Blob storage).
While creating HDInsight Spark Cluster
select Primary Storage Type as Azure Storage & select storage account that
you have created.
Note- for ADF Spark Activity Blob Storage
should be Primary Storage only. You can add ADL as secondary storage if
you want to access input Data from ADL.
3. Create Folder Structure for Spark Job in
Blob Storage.
Once
you create a spark cluster with Storage as Blob Storage, it will create a
container in Blob storage with Cluster name. Create Spark Job folder structure
in this container.
Folder
Structure should be like below.
SparkWordCount
--[ Folder ]
WordCount-0.0.1-SNAPSHOT.jar
--[ File ]
files --[ Folder ]
input1.txt --[ File ]
input2.txt --[ File ]
SparkWordCount.properties --[ File ]
--put all files that want to pass to spark
job
jars --[ Folder ]
package1.jar --[ File ]
package2.jar --[ File ]
--put dependency jars
logs --[ Folder ]
Output --[ Folder ]
How
to create folder in Blob storage.
There
is two way to create folder.
1. Using Azure Storage Explorer. It will be
install on your VM from where you want to access.
2. Using putty . If you are using putty and
creating dir
Hadoop
fs -mkdir
wasbs://<containername>@<accountname>.blob.core.windows.net/<path>
Hadoop
fs -mkdir wasbs://mycontainer@myaccount.blob.core.windows.net/SparkWordCount
It
will not show as folder in Azure portal unless you are not putting any file in
this dir.
How
to create a pipeline with Spark activity.
1. Create a data factory if not exist.
2. Create an Azure Storage linked service to
link your Azure storage that is associated with your HDInsight Spark cluster to
the data factory.
3. Create an Azure HDInsight linked service
to link your Apache Spark cluster in Azure HDInsight to the data factory.
4. Create a dataset that refers to the Azure
Storage linked service. Currently, you must specify an output dataset for an
activity even if there is no output being produced.
5. Create a pipeline with Spark activity that
refers to the HDInsight linked service created in #2. The activity is
configured with the dataset you created in the previous step as an output
dataset.
The
output dataset is what drives the schedule (hourly, daily, etc.). Therefore,
you must specify the output dataset even though the activity does not really
produce an output.
Create
Data Factory
1. Log in to the Azure portal.
2. Click NEW on the left
menu, click Data + Analytics, and click Data Factory.
3. In the New data factory blade,
enter SparkDF for the Name.
4. Select the Azure subscription where
you want the data factory to be created.
5. Select an existing resource group or
create an Azure resource group.
6. Select Pin to dashboard option.
7. Click Create on the New
data factory blade.
8. You see the data factory being created in
the dashboard of the Azure portal as follows:
9. After the data factory has been created
successfully, you see the data factory page, which shows you the contents of
the data factory. If you do not see the data factory page, click the tile for
your data factory on the dashboard.
How to create folder in Blob storage ?
There is two way to create folder.
1. Using Azure Storage Explorer. It will be
install on your VM from where you want to access.
2. Using putty . If you are using putty and
creating dir
Hadoop fs -mkdir
wasbs://<containername>@<accountname>.blob.core.windows.net/<path>
Hadoop fs -mkdir
wasbs://mycontainer@myaccount.blob.core.windows.net/SparkWordCount
It will not show as folder in Azure portal
unless you are not putting any file in this dir.
How to create a pipeline with Spark
activity.
1. Create a data factory if not exist.
2. Create an Azure Storage linked service to
link your Azure storage that is associated with your HDInsight Spark cluster to
the data factory.
3. Create an Azure HDInsight linked service
to link your Apache Spark cluster in Azure HDInsight to the data factory.
4. Create a dataset that refers to the Azure
Storage linked service. Currently, you must specify an output dataset for an
activity even if there is no output being produced.
5. Create a pipeline with Spark activity that
refers to the HDInsight linked service created in #2. The activity is
configured with the dataset you created in the previous step as an output
dataset.
The output dataset is what drives the
schedule (hourly, daily, etc.). Therefore, you must specify the output dataset
even though the activity does not really produce an output.
Create
Data Factory
1. Log in to the Azure portal.
2. Click NEW on the left
menu, click Data + Analytics, and click Data Factory.
3. In the New data factory blade,
enter SparkDF for the Name.
4. Select the Azure subscription where
you want the data factory to be created.
5. Select an existing resource group or
create an Azure resource group.
6. Select Pin to dashboard option.
7. Click Create on the New
data factory blade.
8. You see the data factory being created in
the dashboard of the Azure portal as follows:
9. After the data factory has been created
successfully, you see the data factory page, which shows you the contents of
the data factory. If you do not see the data factory page, click the tile for
your data factory on the dashboard.

Create linked services
In this step, you create two linked
services, one to link your Spark cluster to your data factory, and the other to
link your Azure storage to your data factory.
Create Azure Storage
linked service
In this step, you link your Azure Storage
account to your data factory. A dataset you create in a step later in this
walkthrough refers to this linked service. The HDInsight linked service that
you define in the next step refers to this linked service too.
1. Click Author and deploy on
the Data Factory blade for your data factory. You should see
the Data Factory Editor.
2. Click New data store and
choose Azure storage.

3. You should see the JSON script for
creating an Azure Storage linked service in the editor.

4. Replace account name and account
key with the name and access key of your Azure storage account.
To get account name and account key
Azure Storage Account (Blob Storage) >
Access Key

5. To deploy the linked service, click Deploy on
the command bar. After the linked service is deployed successfully, the Draft-1 window
should disappear and you see AzureStorageLinkedService in the
tree view on the left.
JSON Script ( AzureStorageLinkedService )
{
"name": "AzureStorageLinkedService",
"properties": {
"description": "",
"type": "AzureStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;
AccountName=abc ;AccountKey=****
}
}
}
Create HDInsight linked
service
In this step, you create Azure HDInsight
linked service to link your HDInsight Spark cluster to the data factory. The
HDInsight cluster is used to run the Spark program specified in the Spark
activity of the pipeline in this sample.
1. Click ... More on the toolbar, click New compute, and then click HDInsight cluster.

2. Copy and paste the following snippet to
the Draft-1 window. In the JSON editor, do the following
steps:
1. Specify the URI for the
HDInsight Spark cluster. For example: https://<sparkclustername>.azurehdinsight.net/.
2. Specify the name of the user who
has access to the Spark cluster.
3. Specify the password for
user.
4. Specify the Azure Storage linked
service that is associated with the HDInsight Spark cluster. In this
example, it is: AzureStorageLinkedService.
JSON Script ( HDInsightLinkedService)
{
"name": "HDInsightLinkedService",
"properties": {
"description": "",
"type": "HDInsight",
"typeProperties": {
"clusterUri": "https://<sparkclustername>.azurehdinsight.net",
"userName": "abc",
"password": "*****"
"linkedServiceName": "AzureStorageLinkedService"
}
}
}
Create output dataset
The output dataset is what drives the
schedule (hourly, daily, etc.). Therefore, you must specify an output dataset
for the spark activity in the pipeline even though the activity does not really
produce any output. Specifying an input dataset for the activity is optional.
1. In the Data Factory Editor,
click ... More on the command bar, click New dataset,
and select Azure Blob storage.
2. Copy and paste the following snippet to
the Draft-1 window. The JSON snippet defines a dataset
called OutputDataset.
Blob container created by spark cluster - adfspark
Spark job root folder - SparkWordCount
Job output folder - Output
JSON Script ( WordCountOutputDataset)
{
"name": "WordCountOutputDataset",
"properties": {
"published": false,
"type": "AzureBlob",
"linkedServiceName": "AzureStorageLinkedService",
"typeProperties": {
"fileName": "WordCountOutput.txt",
"folderPath": "adfspark/SparkWordCount/Output",
"format": {
"type":
"TextFormat",
"columnDelimiter":
" "
}
},
"availability": {
"frequency": "Day",
"interval": 1,
"offset": "15:25:00"
}
}
}
Create pipeline
1. In the Data Factory Editor,
click � More on the command bar, and then click New
pipeline.
2. Replace the script in the Draft-1 window
with the following script:
3. The type property is set
to HDInsightSpark.
4. The rootPath is set
to adfspark/SparkWordCount where adfspark is the Azure Blob container
and SparkWordCount is folder in that container. In this example, the Azure
Blob Storage is the one that is associated with the Spark cluster. You can
upload the file to a different Azure Storage. If you do so, create an Azure
Storage linked service to link that storage account to the data factory. Then,
specify the name of the linked service as a value for
the sparkJobLinkedService property.
5. The entryFilePath is set to
the WordCount-0.0.1-SNAPSHOT.jar, which is the spark program jar file.
6. The getDebugInfo property is set
to Always, which means the log files are always generated (success or
failure).
The outputs section has one output dataset. You
must specify an output dataset even if the spark program does not produce any
output. The output dataset drives the schedule for the pipeline (hourly, daily,
etc.).
JSON Script ( WordCountPipeline)
{
"name":
"WordCountPipeline",
"properties": {
"activities": [
{
"type":
"HDInsightSpark",
"typeProperties": {
"rootPath":
"adfspark/SparkWordCount",
"entryFilePath":
"WordCount-0.0.1-SNAPSHOT.jar",
"arguments": [ "arg1", "arg2" ],
"sparkConfig": {
"spark.executor.memory": "512m"
},
"className":
"wordcount.WordCount",
"getDebugInfo":
"Always"
},
"outputs": [
{
"name":
"WordCountOutputDataset"
}
],
"scheduler": {
"frequency":
"Day",
"interval": 1,
"offset":
"15:25:00"
},
"name":
"MySparkActivity",
"description":
"This activity invokes the Spark program",
"linkedServiceName":
"HDInsightLinkedService"
}
],
"start": "2017-05-23T15:24:00Z",
"end": "2017-05-27T00:00:00Z",
"isPaused": false,
"pipelineMode": "Scheduled"
}
}
Monitor pipeline
Click X to close Data Factory Editor blades and to navigate back to the Data Factory home page. Click Monitor and Manage to launch the monitoring application in another tab.


0 Comments
Be first to comment on this post.